
Blog : le développement avec Nextjs
- blog
- nextjs
- react
- ssg
- dev
- web
Introduction
Nous voilà en 2024, alors bonne année 😁 à tous !
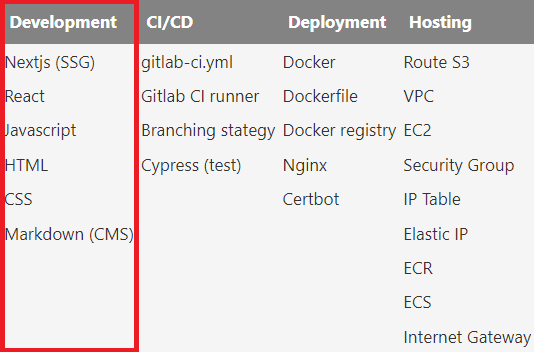 Dernier article consacré au blog sur la thématique des technos utilisées. Après le hosting avec AWS, le déploiement avec Docker et le CI/CD avec Gitlab CI, on va aujourd'hui évoquer le développement avec Nextjs.
Pour rappel mon choix était de faire du Static Site Generation (SSG), et à l'époque où je m'y suis intéressé (fin 2022), Nextjs (version 13) était le framework le plus à la "mode" pour faire du SSG. Aujourd'hui j'aurais peut être considéré d'autres framework tels que Astro ou Gatsby.
Dernier article consacré au blog sur la thématique des technos utilisées. Après le hosting avec AWS, le déploiement avec Docker et le CI/CD avec Gitlab CI, on va aujourd'hui évoquer le développement avec Nextjs.
Pour rappel mon choix était de faire du Static Site Generation (SSG), et à l'époque où je m'y suis intéressé (fin 2022), Nextjs (version 13) était le framework le plus à la "mode" pour faire du SSG. Aujourd'hui j'aurais peut être considéré d'autres framework tels que Astro ou Gatsby.
Base
Pour initier ce blog, je me suis basé sur le template de démarrage du tutoriel dans la documentation Nextjs :
- documentation du tutoriel : https://nextjs.org/learn-pages-router/basics/create-nextjs-app (on s'arrête à la fin du chapitre "Dynamic Routes")
- repo github : https://github.com/vercel/next-learn/tree/main/basics/api-routes-starter
- setup :
npx create-next-app@latest nextjs-blog --use-npm -example "https://github.com/vercel/next-learn/tree/main/basics/api-routes-starter" - résultat : https://next-learn-starter.vercel.app/
Arborescence fichiers
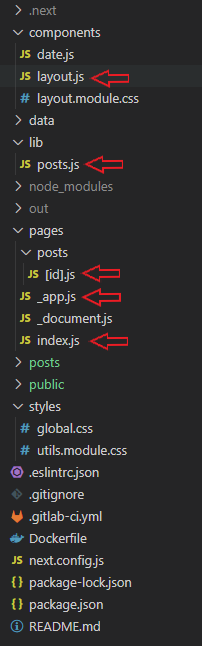
Le contenu du répertoire "./pages/" est interprété par Nextjs comme le routage du site (la récursivité est prise en compte). Seuls les fichiers préfixés par "_" ne font pas partie du routage.
- _app.js : point d'entrée Nextjs
- index.js : définit la homepage
- [id].js : définit les pages article (posts). La syntaxe "id" entre crochets indique que le nommage de la page "[id].js" est dynamique
- posts.js : contient la logique pour parser les fichiers markdown et fetch les data des articles. Appellé par "index.js" et "[id].js"
- layout.js : définit le squelette global du site web (header, main, footer). Appellé par "index.js" et "[id].js"
Fetching et pre-rendering
Le principe du SSG est de pré-rendre les données et chemins de manière exhaustive au moment du build pour pouvoir générer en sortie l'ensemble des fichiers du site web qui seront servis par un serveur web ou via un cache CDN. Pour ce faire, Nextjs met à disposition deux fonctions : getStaticProps et getStaticPaths. Il est important de respecter le nommage de ces deux fonctions.
Fonction getStaticProps
getStaticProps est une fonction Nextjs pour le SSG qui permet de fetch de la data au moment du build pour faire du pre-rendering.
- utilisation dans le fichier "index.js" ("getSortedPostsData") :
import { getSortedPostsData } from '../lib/posts'
/*
...
*/
export async function getStaticProps() {
const allPostsData = getSortedPostsData()
return {
props: {
allPostsData
}
}
}
L'object retourné "allPostsData" est un array qui contient pour chaque article les propriétés : title, id, image, date et tags. Ces propriétés sont utilisées pour contruire la liste des articles, rechercher par titre et filtrer par tag dans la homepage.
- utilisation dans le fichier "[id].js" ("getPostData") :
import { getAllPostIds, getPostData } from '../../lib/posts'
/*
...
*/
export async function getStaticProps({ params }) {
const postData = await getPostData(params.id)
return {
props: {
postData
}
}
}
L'object retourné "postData" contient les propriétés de l'article : title, id, image, date, tags et contentHtml. Ces propriétés sont utlisées pour construire la page de l'article.
Nous verrons un peu plus bas (dans la partie markdown) le détail du fichier "posts.js" qui récupére les données des articles en allant parser les fichiers markdown (.md).
Fonction getStaticPaths
La fonction getStaticPaths quant à elle permet de construire dynamiquement des pages (donc des routes). Dans notre cas : un article = une page dans "/posts/" avec comme nom le slug du titre de l'article (on remplace les espaces par des "-").
- utilisation dans le fichier "[id].js" ("getAllPostIds") :
import { getAllPostIds, getPostData } from '../../lib/posts'
/*
...
*/
export async function getStaticPaths() {
const paths = getAllPostIds()
return {
paths,
fallback: false
}
}
L'object retourné "paths" est un array qui contient pour chaque article la propriété params :
{ params: {
id: fileName.replace(/\.md$/, '')
}
}
Lors du build, Nextjs va pré-rendre autant de pages qu'il y a d'articles.
Personnalisation
Maintenant qu'on a la base du blog, on va pouvoir personnaliser afin d'implémenter ce qu'on souhaite mettre en place.
Design UI
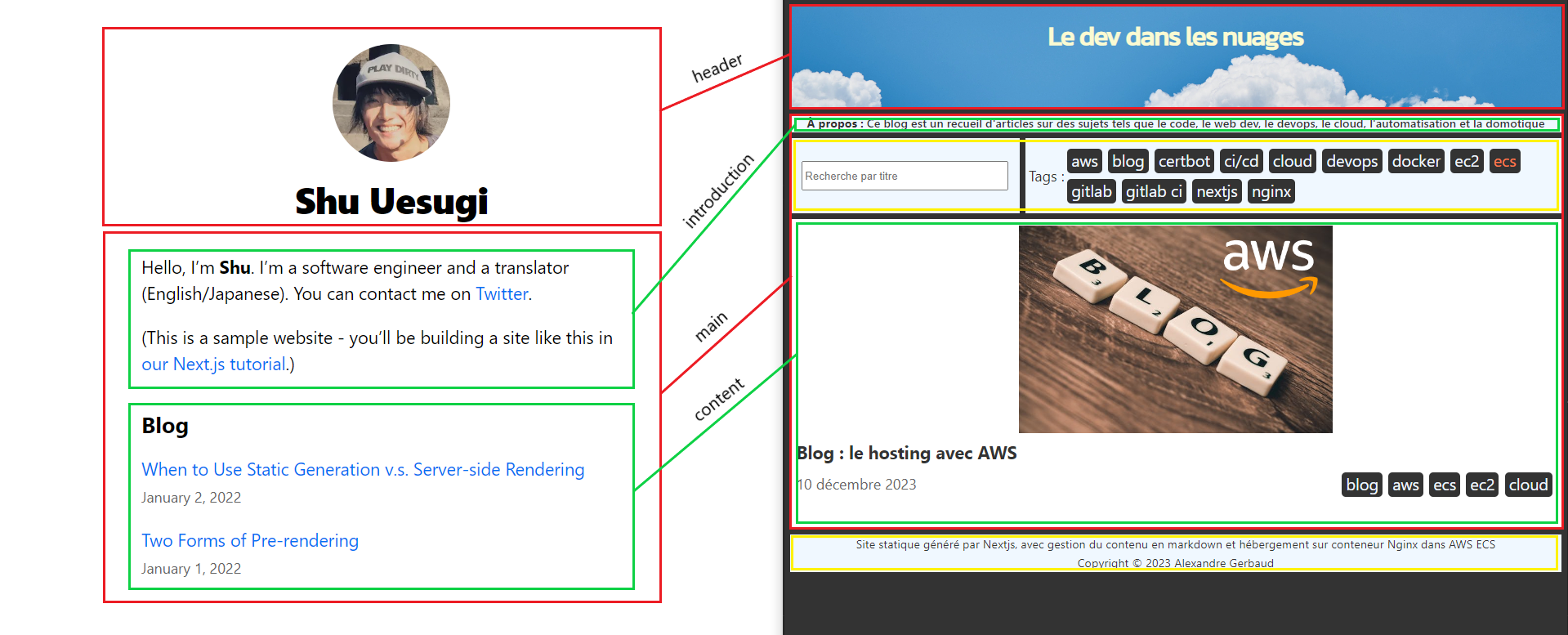 Plus je fait du dev web et plus je me rend compte que je suis mauvais pour tout ce qui touche au design et à l'UI.
Donc ça me prend énormément de temps, et pour au final un résultat qui ne me satisfait jamais. On fait avec, je me dis qu'un jour je ferai mieux 😁
Plus je fait du dev web et plus je me rend compte que je suis mauvais pour tout ce qui touche au design et à l'UI.
Donc ça me prend énormément de temps, et pour au final un résultat qui ne me satisfait jamais. On fait avec, je me dis qu'un jour je ferai mieux 😁
Au niveau du layout, quelques changements ont été opérés par rapport au template initial, et de nouveaux éléments on été ajoutés (encadrés en jaune) :
- une section entre l'introduction et le content pour la recherche par titre et le filtrage par tags
- un footer en bas de chaque pages
Pour le responsive, j'ai ajouté quelques media queries et j'ai essayé de gérer de manière empirique (par itération) en jouant sur les valeurs des media queries et en controlant avec l'inspecteur de chrome :
@media screen and (min-width: 590px) {
.articleContent table {
font-size: 11px;
}
.articleContent pre {
font-size: 14px;
}
}
@media screen and (min-width: 850px) {
.articleContent table {
font-size: 17px;
}
.articleContent pre {
font-size: 18px;
}
}
Ajout de metadata pour le frontmatter
Le frontmatter est un moyen de spécifier des metadata dans les fichiers markdown. Ces metadata sont renseignées en début de fichier et sont entourées par deux "---", ce qui permet au parser les reconnaitre. Le template initial embarque deux metadata : title et date. Je conserve ces deux metadata, mais je vais aussi en ajouter de nouvelles :
- tags : array qui liste les tags associés à l'article. Ces tags sont utilisés par la fonctionnalité de filtrage en homepage.
- image : string qui représente le chemin de l'image associée à l'article. Cette image est affichée au tout début de l'article et apparait également dans la liste des articles en homepage
Exemple :
---
title: 'Pourquoi ce blog ?'
date: '2023-12-03'
tags:
- 'blog'
- 'nextjs'
- 'gitlab ci'
- 'docker'
- 'aws'
image: '/images/pourquoi-ce-blog/blog.jpg'
---
Nouvelles fonctionnalités homepage
 J'ai voulu implémenter deux nouvelles fonctionnalités pour tirer parti du côté dynamique de react et pour améliorer l'expérience utilisateur :
J'ai voulu implémenter deux nouvelles fonctionnalités pour tirer parti du côté dynamique de react et pour améliorer l'expérience utilisateur :
- recherche par titre : input de type texte qui met à jour le hook "textSearch" à chaque nouvelle valeur. "textSearch" est ensuite utilisé (ligne 91) dans le return pour filtrer sur la propriété title
- filtrage par tags : inputs cliquables qui représentent la liste de valeurs uniques des tags utilisés dans tous les articles (hook "availableTagsList"). Le fonctionnement est celui d'un toggle (on/off), et le style de l'élément est modifié en fonction de la valeur du toggle. Le hook "checkedTags" trace les tags sélectionnés, et est utilisé (ligne 95) dans le return pour filtrer sur la propriété tags . Quand on sélectionne plusieurs tags, c'est une opération "AND" (et pas "OR"), ce qui permet de durcir la recherche
Code :
import Head from 'next/head'
import Layout, { siteTitle } from '../components/layout'
import utilStyles from '../styles/utils.module.css'
import { getSortedPostsData } from '../lib/posts'
import Link from 'next/link'
import Date from '../components/date'
import Image from 'next/image';
import React, { useEffect, useState } from 'react';
export default function Home({ allPostsData }) {
// Hook useState (permet de relancer un rendu (Home) dès qu'une fonction setxxx est lancée)
const [textSearch, setTextSearch] = useState("");
const [checkedTags, setCheckedTags] = useState([]);
const [availableTagsList, setAvailableTagsList] = useState([]);
// Hook useEffect
// Quand callback = [] -> Permet de n'exécuter useEffect qu'une seule fois au début
// Quand callback = [data, rangeValue] -> Permet d'exécuter useEffect à chaque fois que data ou rangeValue change
useEffect(() => {
const getData = async () => {
// determine unique tags list
var tagsList = [];
for(var postData of allPostsData) {
tagsList = [...tagsList, ...postData.tags]; // equivant : tagsList = tagsList.concat(postData.tags);
}
tagsList = [...new Set(tagsList)];
tagsList = tagsList.sort();
setAvailableTagsList(tagsList);
}
getData();
}, []);
function handleSearchChangeText(e) {
setTextSearch(e.target.value);
}
function handleSearchChangeTag(tagElem) {
// add tag to list
// if (tagElem.target.checked) {
if (tagElem.target.style.color == "aliceblue") {
tagElem.target.style.color = "coral";
setCheckedTags((previousTagsList) => {
var newTagsList = [...previousTagsList, tagElem.target.innerText];
return newTagsList;
})
// remove tag from list
} else {
tagElem.target.style.color = "aliceblue"
setCheckedTags((previousTagsList) => {
var newTagsList = previousTagsList.filter((tag) => tag != tagElem.target.innerText);
return newTagsList;
})
}
}
return (
<Layout home>
<Head>
<title>{siteTitle}</title>
</Head>
<section className={utilStyles.introductionSection}>
<p className={utilStyles.introductionParagraph}><b>{"À propos : "}</b>{"Ce blog est un recueil d'articles sur des sujets tels que le code, le web dev, le devops, le cloud, l'automatisation et la domotique"}</p>
</section>
<section className={utilStyles.searchAndTags}>
<div className={utilStyles.searchDiv}>
<input type="text" name="searchTitle" id="searchTitle" className={utilStyles.searchTitle} placeholder="Recherche par titre" onChange={(e) => handleSearchChangeText(e)}></input>
</div>
<div className={utilStyles.tagsDiv}>
<label htmlFor="searchTags">Tags : </label>
<ul name="searchTags" id="searchTags" className={utilStyles.searchTags}>
{availableTagsList.map((tag) => {
return (
<li onClick={(e) => handleSearchChangeTag(e)} className={`${utilStyles.listItemTag} ${utilStyles.pointer}`} style={{color: "aliceblue"}} key={tag}>{tag}</li>
)
})}
</ul>
</div>
</section>
<section className={`${utilStyles.headingMd}`}>
<ul className={utilStyles.list}>
{allPostsData
// filtre par text dans le titre
.filter(({ title }) => {
return (title.indexOf(textSearch) != -1);
})
// filtre par tags
.filter(({ tags }) => {
var matchTags = true;
for (var tag of checkedTags) {
if (!tags.includes(tag)) {
matchTags = false;
break;
}
}
return matchTags;
})
.map(({ id, date, title, tags, image }) => (
<li className={utilStyles.listItem} key={id}>
<div className={utilStyles.listItemImage}>
<Image
src={image} // Route of the image file
fill
style={{objectFit:"contain"}}
alt={`${id}-img`}
/>
</div>
<Link href={`/posts/${id}`}>{title}</Link>
<br />
<div className={utilStyles.listItemDateAndTags}>
<small className={utilStyles.lightText}>
<Date dateString={date} />
</small>
<ul>
{tags.map((tag, index) => (
<li key={index} className={utilStyles.listItemTag}>{tag}</li>
))}
</ul>
</div>
</li>
))
}
</ul>
</section>
</Layout>
)
}
export async function getStaticProps() {
const allPostsData = getSortedPostsData()
return {
props: {
allPostsData
}
}
}
Le hook useEffect est déclenché qu'une seule fois au premier chargement de la page et permet de calculer la liste des tags (ligne 30). Un event listener est positionné sur chacun des inputs en inline (lignes 73 et 80). Ces event listener déclenchent des fonctions pour gérer les changements d'input de recherche par titre (handleSearchChangeText) et de filtrage par tags (handleSearchChangeTag). Ces changements d'inputs mettent à jour les states textSearch et checkedTags qui déclenchent un nouveau rendu.
Gestion du contenu
Avec Nextjs, il y a deux options pour gérer les données (fetch) :
- en local via fichiers markdown (1 fichier par article)
- fetch external data source (DB, API)
J'ai donc choisi markdown en tant que CMS (Content Management System). Pourquoi ? Parce que c'était la solution la plus simple, la mieux documentée et ca me permettait de gagner en aisance dessus (sachant que c'est couramment utilisé dans les projets Git). Il n'y a rien de sorcier à apprendre markdown, d'ailleurs on s'en sort très bien avec le cheatsheet.
Un fichier markdown se décompose en deux parties :
- le frontmatter : en yaml, représente les metadata
- le contenu : en markdown, représente le contenu
Fichier "posts.js" :
import fs from 'fs'
import path from 'path'
import matter from 'gray-matter'
import { remark } from 'remark'
import html from 'remark-html'
// import { unified } from 'unified'
// import remarkParse from 'remark-parse'
// import remarkRehype from 'remark-rehype'
// import rehypeStringify from 'rehype-stringify'
import remarkGfm from 'remark-gfm'
import remarkHeadingId from 'remark-heading-id'
import emoji from 'remark-emoji'
import remarkPrism from "remark-prism"
const postsDirectory = path.join(process.cwd(), 'posts')
export function getSortedPostsData() {
// Get file names under /posts
const fileNames = fs.readdirSync(postsDirectory)
const allPostsData = fileNames.map(fileName => {
// Remove ".md" from file name to get id
const id = fileName.replace(/\.md$/, '')
// Read markdown file as string
const fullPath = path.join(postsDirectory, fileName)
const fileContents = fs.readFileSync(fullPath, 'utf8')
// Use gray-matter to parse the post metadata section
const matterResult = matter(fileContents)
// Combine the data with the id
return {
id,
...matterResult.data
}
})
// Sort posts by date
return allPostsData.sort((a, b) => {
if (a.date < b.date) {
return 1
} else {
return -1
}
})
}
export function getAllPostIds() {
const fileNames = fs.readdirSync(postsDirectory)
return fileNames.map(fileName => {
return {
params: {
id: fileName.replace(/\.md$/, '')
}
}
})
}
export async function getPostData(id) {
const fullPath = path.join(postsDirectory, `${id}.md`)
const fileContents = fs.readFileSync(fullPath, 'utf8')
// Use gray-matter to parse the post metadata section
const matterResult = matter(fileContents)
// Use remark to convert markdown into HTML string
const processedContent = await remark()
html, { sanitize: false })
remarkGfm)
remarkHeadingId, {defaults: true})
emoji)
remarkPrism, { plugins: ["line-numbers"] })
.process(matterResult.content)
const contentHtml = processedContent.toString()
// const processedContent = await unified()
// remarkParse)
// remarkGfm)
// remarkRehype)
// rehypeStringify)
// .process(matterResult.content)
// const contentHtml = String(processedContent)
// Combine the data with the id and contentHtml
return {
id,
contentHtml,
...matterResult.data
}
}
Pour interpréter et traduire le frontmatter et le markdown il faut utiliser des parser :
- matter permet de parser le frontmatter
- remark permet de parser le markdown
Des middleware / plugins sont également nécessaire pour ajouter des fonctionnalités supplémentaires :
html, { sanitize: false }: permet de traduire le markdown en language HTMLremarkGfm: ajoute des fonctionnalités avancées comme les tablesremarkHeadingId, {defaults: true}: ajoute un id html aux titresemoji: prend en charge les emojiremarkPrism, { plugins: ["line-numbers"] }: sert à formater les bloc de code et à ajouter les numéros de ligne
Génération du contenu statique
En mode développement ou rédaction d'article, on utilise npm run dev (next dev) en local pour démarrer un serveur web (par défaut http://localhost:3000). Tout comme react, il y rechargement et compilation automatique lorsqu'on modifie et enregistre du code (à noter que ca ne fonctionne pas pour les fichiers .md, donc il faut interrompre et relancer le serveur).
Pour builder l'application on utilise npm run build (next build && next export). Les fichiers statiques sont alors exportés dans le répertoire "./out/".
Le mot de la fin
Ce qui est cool c'est que ce blog s'auto alimente. Déjà 5 articles 😉 C'en est terminé pour cette série d'articles, pour la suite j'écrirai quand le besoin / l'inspiration se fera sentir, et quand j'aurai de la matière. Sur ce, à la prochaine pour un autre sujet pour l'instant inconnu ;)